- 프로그래밍에서의 좌표계는 일반적인 대수학에서의 좌표계와 다른 의미를 가질 때가 많습니다.
- 일반적으로 알고리즘 문제에서의 2차원 공간을 행렬(Matrix)의 의미로 사용됩니다.
- 완전 탐색 문제에서는 2차원 공간에서의 방향 벡터가 자주 활용됩니다.
<문제> 시각: 문제 설명
- 정수 N이 입력되면 00시 00분 00초부터 N시 59분 59초까지의 모든 시각 중에서 3이 하나라도 포함되는 모든 경우의 수를 구하는 프로그램을 작성하세요. 예를 들어 1을 입력했을 때 다음은 3이 하나라도 포홤되어 있으므로 세어야 하는 시각입니다.
- 00시 00분 03초
- 00시 13분 30초
- 반면에 다음은 3이 하나도 포함되어 있지 않으므로 세면 안 되는 시각입니다.
- 00시 02분 55초
- 01시 27분 45초
<문제> 시각: 문제 조건
<문제> 시각: 문제 해결 아이디어
- 이 문제는 가능한 모든 시각의 경우를 하나씩 모두 세서 풀 수 있는 문제입니다.
- 하루는 86,400초이므로, 00시 00분 00초부터 23시 59분 59초까지의 모든 경우는 86,400가지 입니다.
- 24 * 60 * 60 = 86,400
- 따라서 단순히 시각을 1씩 증가시키면서 3이 하나라도 포함되어 있는지를 확인하면 됩니다.
- 이러한 유형은 완전 탐색(Brute Forcing) 문제 유형이라고 불립니다.
- 가능한 경우의 수를 모두 검사해보는 탐색 방법을 의미합니다.
<문제> 시각: 답안 예시 (Python)
# H 입력 받기
h = int(input())
count = 0
for i in range(h + 1):
for j in range(60):
for k in range(60):
# 매 시각 안에 '3'이 포함되어 있다면 카운트 증가
if '3' in str(i) + str(j) + str(k):
count += 1
print(count)
<문제> 상하좌우: 문제 설명
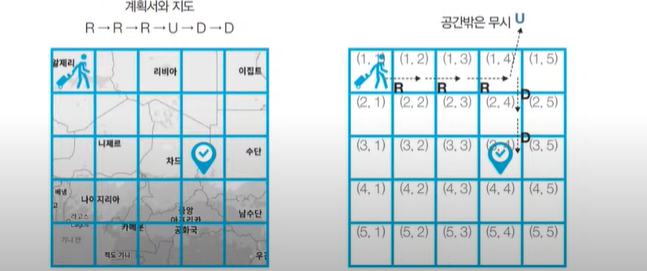
- 여행가 A는 N x N 크기의 정사각형 공간 위에 서 있습니다. 이 공간은 1 x 1 크기의 정사각형으로 나누어져 있습니다. 가장 왼쪽 위 좌표는 (1, 1)이며, 가장 오른쪽 아래 좌표는 (N, N)에 해당합니다. 여행가 A는 상, 하, 좌, 우 방향으로 이동할 수 있으며, 시작 좌표는 항상 (1, 1)입니다. 우리 앞에는 여행가 A가 이동할 계획이 적힌 계획서가 놓여 있습니다.
- 계획서에는 하나의 줄에 띄어쓰기를 기준으로 하여 L, R, U, D중 하나의 문자가 반복적으로 적혀 있습니다. 각 문자의 의미는 다음과 같습니다.
- L: 왼쪽으로 한 칸 이동
- R: 오른쪽으로 한 칸 이동
- U 위로 한 칸 이동
- D: 아래로 한 칸 이동
- 이때 여행가 A가 N x N 크기의 정사각형 공간을 벗어나는 움직임은 무시됩니다. 예를 들어 (1, 1)의 위치에서 L 혹은 U를 만나면 무시됩니다. 다음은 N = 5인 지도와 계획서입니다.
<문제> 상하좌우: 문제 조건
<문제> 상하좌우: 문제 해결 아이디어
- 이 문제는 요구사항대로 충실히 구현하면 되는 문제입니다.
- 일련의 명령에 따라서 개체를 차례대로 이동시킨다는 점에서 시뮬레이션(Simulation) 유형으로도 분류되며 구현이 중요한 대표적인 문제 유형입니다.
<문제> 상하좌우: 답안 예시 (Python)
# N 입력 받기
n = int(input())
x, y = 1, 1
plans = input().split()
# L, R, U, D 에 따른 이동 방향
dx = [0, 0, -1, 1]
dy = [-1, -1, 0, 0]
move_types = ['L', 'R', 'U', 'D']
# 이동 계획을 하나씩 확인하기
for plan in plans:
# 이동 후 좌표 구하기
for i in range(len(voe_types)):
if plan == move_types[i]:
nx = x + dx[i]
ny = y + dy[i]
# 공간을 벗어나는 경우 무시
if nx < 1 or ny < 1 or nx > n or ny > n:
continue
# 이동 수행
x, y = nx, ny
print(x, y)
<문제> 문자열 재정렬: 문제 설명
- 알파벳 대문자와 숫자(0 ~ 9)로만 구성된 문자열이 입력으로 주어집니다. 이때 모든 알파벳을 오름차순으로 정렬하여 이어서 출력한 뒤에, 그 뒤에 모든 숫자를 더한 값을 이어서 출력합니다.
<문제> 문자열 재정렬: 문제 조건
<문제> 문자열 재정렬: 문제 해결 아이디어
- 문자열이 입력되었을 때 문자를 하나씩 확인합니다.
<문제> 문자열 재정렬: 답안 예시 (Python)
data = input()
result = []
value = 0
# 문자를 하나씩 확인하며
for x in data:
# 알파벳인 경우 결과 리스트에 삽입
if x.isalpha():
result.append(x)
# 숫자는 따로 더하기
else:
value += int(x)
# 알파벳을 오름차순으로 정렬
result.sort()
# 숫자가 하나라도 존재하는 경우 가장 뒤에 삽입
if value != 0:
result.append(str(value))
# 최종 결과 출력(리스트를 문자열로 변환하여 출력)
print(''.join(result))
- 일반적인 그리디 알고리즘은 문제를 풀기 위한 최소한의 아이디어를 떠올릴 수 있는 능력을 요구합니다.
- 정당성 분석이 중요
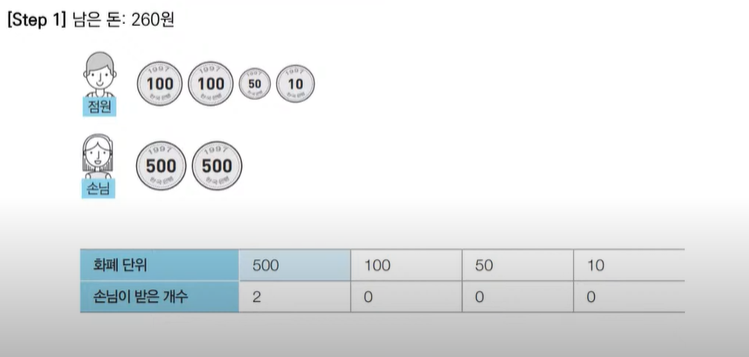
<문제> 거스름 돈: 문제 설명
- 최적의 해를 빠르게 구하기 위해서는 가장 큰 화폐 단위부터 돈을 거슬러 주면 된다.
<문제> 거스름 돈: 정당성 분석
- 가장 큰 화폐 단위부터 돈을 거슬러 주는 것이 최적의 해를 보장하는 이유는?
- 가지고 있는 동전 중에서 큰 단위가 항상 작은 단위의 배수이므로 작은 단위의 동전들을 종합해 다른 해가 나올 수 없기 때문입니다.
<문제> 거스름 돈: 답안 예시(Python)
n = 1260
count = 0
# 큰 단위의 화폐부터 차례대로 확인하기
array = [500, 100, 50, 10]
for coin in array:
count += n // coin # 해당 화폐로 거슬러 줄 수 있는 동전의 개수 세기
n %= coin
print(count)
<문제> 거스름 돈: 시간 복잡도 분석
- 화폐의 종류가 K라고 할 때, 소스코드의 시간 복잡도는 O(K)입니다.
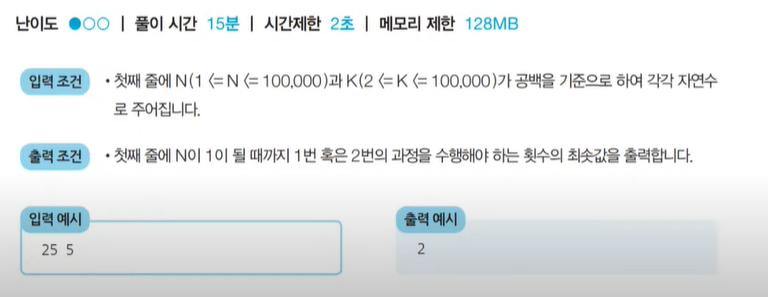
<문제> 1이 될 때까지: 문제 설명
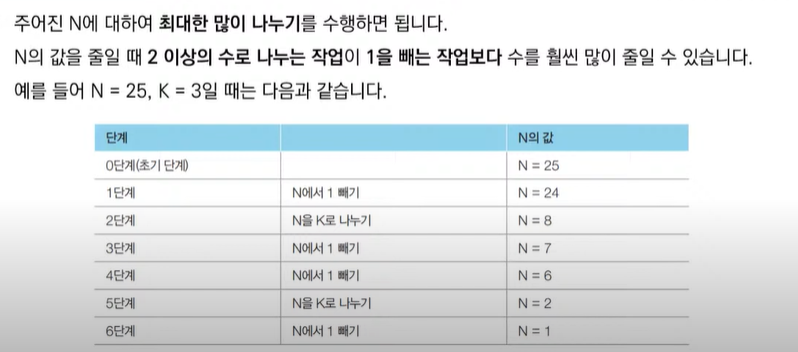
- 어떠한 수 N이 1이 될 때까지 다음의 두 과정 중 하나를 반복적으로 선택하여 수행하려고 합니다. 단, 두번째 연산은 N이 K로 나누어 떨어질 때만 선택할 수 있습니다.
1. N에서 1을 뺍니다.
2. N을 K로 나눕니다.
- 예를 들어 N이 17, K가 4라고 가정합시다. 이때 1번의 과정을 한 번 수행하면 N은 16이 됩니다. 이후에 2번의 과정을 두 번 수행하면 N은 1이됩니다. 결과적으로 이 경우 전체 과정을 실행한 횟수는 3이 됩니다. 이는 N을 1로 만드는 최소 횟수입니다.
- N과 K가 주어질 때 N이 1이 될 때까지 1번 혹은 2번의 과정을 수행해야 하는 최소 횟수를 구하는 프로그램을 작성하세요.
<문제> 1이 될 때까지: 문제 조건
<문제> 1이 될 때까지: 문제 해결 아이디어
<문제> 1이 될 때까지: 정당성 분석
- 가능하면 최대한 많이 나누는 작업이 최적의 해를 항상 보장할 수 있을까요?
- N이 아무리 큰 수여도, K로 계속 나눈다면 기하급수적으로 빠르게 줄일 수 있습니다.
<문제> 1이 될 때까지: 답안 예시 (Python)
# N, K을 공백을 기준으로 구분하여 입력 받기
n, k = map(int, input().split())
result = 0
while True:
# N이 K로 나누어 떨어지는 수가 될 때까지만 1씩 빼기
target = (n // k) + k
result += (n - target)
n = target
# N이 K보다 작을 때 (더 이상 나눌 수 없을 때) 반복문 탈출
if n < k:
break
# K로 나누기
result += 1
n //= k
# 마지막으로 남은 수에 대하여 1씩 빼기
result += (n - 1)
print(result)
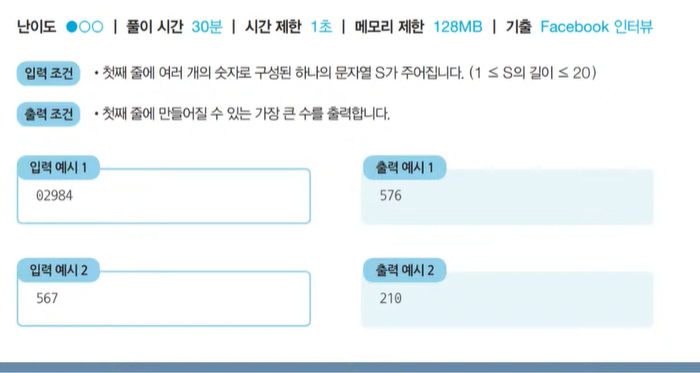
<문제> 곱하기 혹은 더하기: 문제 설명
- 각 자리가 숫자(0부터 9)로만 이루어진 문자열 S가 주어졌을 때, 왼쪽부터 오른쪽으로 하나씩 모든 숫자를 확인하며 숫자 사이에 'x' 혹은 '+' 연산자를 넣어 결과적으로 만들어질 수 있는 가장 큰 수를 구하는 프로그램을 작성하세요. 단, +보다 x 를 먼저 계산하는 일반적은 방식과는 달리, 모든 연산은 왼쪽부터 순서대로 이루어진다고 가정합니다.
<문제> 곱하기 혹은 더하기: 문제 조건
<문제> 곱하기 혹은 더하기: 문제 해결 아이디어
- 대부분의 경우 '+'보다는 'x'가 더 값을 크게 만듭니다.
- 예를 들어 5 + 6 = 11이고, 5 x 6 = 30입니다.
- 다만 두 수 중에서 하나라도 '0' 혹은 '1'인 경우, 곱하기보다는 더하기를 수행하는 것이 효율적입니다.
- 따라서 두 수에 대하여 연산을 수행할 때, 두 수 중에서 하나로 1 이하인 경우에는 더하며, 두 수가 모두 2 이상인 경우에만 곱하면 정답입니다.
<문제> 곱하기 혹은 더하기: 답안 예시 (Python)
data = input()
# 첫 번째 문자를 숫자로 변경하여 대입
result = int(data[0])
for i in range(1, len(data)):
# 두 수 중에서 하나라도 '0' 혹은 '1'인 경우, 곱하기보다는 더하기 수행
num = int(data[i])
if num <= 1 or result <= 1:
result += num
else:
result *= num
print(result)
def add(a, b):
print('함수의 결과: ', a + b)
add(3, 7) # 함수의 결과: 10
파라미터 지정하기
- 파라미터의 변수를 직접 지정할 수 있습니다.
- 이 경우 매개변수의 순서가 달라도 상관이 없습니다.
def add(a, b):
print('함수의 결과: ', a + b)
print(b = 3, a = 7) # 함수의 결과: 10
global 키워드
- global 키워드로 변수를 지정하면 해당 함수에서는 지역 변수를 만들지 않고, 함수 바깥에 선언된 변수를 바로 참조하게 됩니다.
a = 0
def func():
global a
a += 1
for i in range(10):
func()
print(a) # 10
여러 개의 반환 값
- 파이썬에서 함수는 여러 개의 반환 값을 가질 수 있습니다.
def operator(a, b):
add_var = a + b
subtract_var = a - b
multiply_var = a * b
divide_var = a / b
return add_var, subtract_var, multiply_var, divide_var
a, b, c, d = operator(7, 3)
print(a, b, c, d)
람다 표현식
- 람다 표현식을 이용하면 함수를 매우 간단하게 작성할 수 있습니다.
- 특정한 기능을 수행하는 함수를 한 줄에 작성할 수 있다는 점이 특징입니다.
def add(a, b):
return a + b
# 일반적인 add() 메서드 사용
print(add(3, 7)) # 10
# 람다 표현식으로 구현한 add() 메서드
print((lambda a, b: a + b)(3, 7)) # 10
- {'A', 'B', 'C'}에서 두 개를 선택하여 나열하는 경우: 'ABC', 'ACB', 'BAC', 'BCA', 'CAB', 'CBA'
from itertools import permutations
data = ['A', 'B', 'C'] # 데이터 준비
result = list(permutations(data, 3)) # 모든 순열 구하기
print(result)
- 조합: 서로 다른 n개에서 순서에 상관 없이 서로 다른 r개를 선택하는 것
- {'A', 'B', 'C'}에서 순서를 고려하지 않고 두 개를 뽑는 경우: 'AB', 'AC', 'BC'
from itertools import combinations
data = ['A', 'B', 'C'] # 데이터 준비
result = list(combinations(data, 2)) # 2개를 뽑는 모든 조합 구하기
print(result) # [('A','B'), ('A', 'C'), ('B','C')]
- 여러 개의 데이터를 담는 자료형을 위해 in 연산자와 not in 연산자가 제공됩니다.
- 리스트 , 튜플, 문자열, 딕셔너리 모두에서 사용이 가능합니다.
파이썬의 pass 키워드
- 조건문의 값이 참(True)이라고 해도, 아무것도 처리하고 싶지 않을 때 pass 키워드를 사용합니다.
반복문
- 특정한 소스코드를 반복적으로 실행하고자 할 때 사용하는 문법입니다.
- 무한 루프(Infinite Loop): 계속해서 반복되는 반복 구문
1부터 9까지 각 정수의 합 구하기
i = 1
result = 0
# i가 9보다 작거나 같을 때 아래 코드를 반복적으로 실행
while i <= 9:
result += i
i += 1
print(result) # 45
1부터 9까지 홀수의 합 구하기
i = 1
result = 0
# i가 9보다 작거나 같을 때 아래 코드를 반복적으로 실행
while i <= 9:
if i % 2 == 1:
result += i
i += 1
print(result) # 25
반복문: for문
- 반복문으로 for문을 이용할 수도 있습니다.
- for문의 구조는 다음과 같은데, 특정한 변수를 이용하여 'in' 뒤에 오는 자료형(리스트, 튜플 등)에 포함
되어 있는 원소를 첫 번째 인덱스부터 차례대로 하나씩 방문합니다.
for 변수 in 리스트:
실행할 소스코드
- for문에서 수를 차례대로 나열할 때는 range()를 주로 사용합니다.
- 이때 range(시작 값, 끝 값) 형태로 사용합니다.
- 인자를 하나만 넣으면 자동으로 시작 값은 0이 됩니다.
result = 0
# i는 1부터 9까지의 모든 값을 순회
for i in range(1, 10):
result += i
print(result) # 45
학생들의 합격 여부 판단 예시 1) 점수가 80점만 넘으면 합격
scores = [90, 85, 77, 65, 97]
for i in range(5):
if scores[i] >= 80:
print(i + 1, "번 학생은 합격입니다.")
'''
1 번 학생은 합격입니다.
2 번 학생은 합격입니다.
5 번 학생은 합격입니다.
'''
학생들의 합격 여부 판단 예시 2) 특정 번호의 학생은 제외하기
scores = [90, 85, 77, 65, 97]
cheating_student_list = {2, 4}
for i in range(5):
if i + 1 in cheating_student_list:
continue
if scores[i] >= 80:
print(i + 1, "번 학생은 합격입니다.")
'''
1 번 학생은 합격입니다.
5 번 학생은 합격입니다.
'''
중첩된 반복문: 구구단 예시
for i in range(2, 10):
for j in range(1, 10):
print(i, "X", j, "=", i * j)
print()
- 혹은 백슬래시(\)를 사용하면, 큰따옴표나 작은따옴표를 원하는 만큼 포함시킬 수 있습니다.
data = 'Hello World'
print(data) # Hello World
data = "Don't you know \"Python\""
print(data) # Don't you know "Python"?
문자열 연산
- 문자열 변수에 덧셈(+)을 이용하면 문자열이 더해져서 연결(Concatenate)됩니다.
- 문자열 변수를 특정한 양의 정수와 곱하는 경우, 문자열이 그 값만큼 여러 번 더해집니다.
- 파이썬은 문자열은 내부적으로 튜플과 유사하게 처리됩니다.
- 문자열에 대해서도 마찬가지로 인덱싱과 슬라이싱을 이용할 수 있습니다.
리스트의 인덱싱과 슬라이싱
a = "Hello"
b = "World"
print(a + " " + b) # Hello World
a = "String"
print(a * 3) # StringStringString
a = "ABCDEF"
print(a[2:4]) # CD
튜플 자료형
- 튜플 자료형은 리스트와 유사하지만 다음과 같은 문법적 차이가 있습니다.
- 튜플은 한 번 선언된 값을 변경할 수 없습니다.
- 리스트는 대괄호([])를 이용하지만, 튜플은 소괄호(())를 이용합니다.
- 튜플은 리스트에 비해 상대적으로 공간 효율적입니다.
사전 자료형
- 사전 자료형은 키(Key)와 값(Value)의 쌍을 데이터로 가지는 자료형입니다.
- 앞서 다루었던 리스트나 튜플이 값을 순차적으로 저장하는 것과는 대비됩니다.
- 사전 자료형은 키와 값의 쌍을 데이터로 가지며, 원하는 '변경 불가능한(Immutable) 자료형'을 키로 사용할 수 있습니다.
- 파이썬의 사전 자료형은 해시 테이블(Hash Table)을 이용하므로 데이터의 검색 및 수정에 있어서 O(1)의 시간에 처리할 수 있습니다.
data = dict()
data['사과'] = 'Apple'
data['바나나'] = 'Banana'
data['코코넛'] = 'Coconut'
print(data) # {'사과': 'Apple', '바나나': 'Banana', '코코넛': 'Coconut'}
if '사과' in data:
print("'사과'를 키로 가지는 데이터가 존재합니다.") # '사과'를 키로 가지는 데이터가 존재합니다.
사전 자료형 관련 메서드
- 사전 자료형에서는 키와 값을 별도로 뽑아내기 위한 메서드 존재
- 키 데이터만 뽑아서 리스트로 이용할 때는 keys() 함수를 이용합니다.
- 값 데이터만을 뽑아서 리스트로 이용할 때는 values() 함수를 이용합니다.
사전 자료형 관련 함수
data = dict()
data['사과'] = 'Apple'
data['바나나'] = 'Banana'
data['코코넛'] = 'Coconut'
# 키 데이터만 담은 리스트
key_list = data.keys()
# 값 데이터만 담은 리스트
value_list = data.values()
print(key_list)
print(value_list)
# 각 키에 따른 값을 하나씩 출력
for key in key_list:
print(data[key])
집합 자료형
- 집합은 다음과 같은 특징이 있습니다.
- 중복을 허용하지 않습니다.
- 순서가 없습니다.
- 리스트나 튜플은 순서가 있기 때문에 인덱싱을 통해 자료형의 값을 얻을 수 있습니다.
- 사전 자료형과 집합 자료형은 순서가 없기 때문에 인덱싱으로 값을 얻을 수 없습니다.
- 집합은 리스트 혹은 문자열을 이용해서 초기화할 수 있습니다.
- 이때 set() 함수를 이용합니다.
- 혹은 중괄호 ({})안에 각 원소를 콤마(,)를 기준으로 구분하여 삽입함으로써 초기화 할 수 있습니다.
# 집합 자료형 초기화 방법 1
data = set([1, 1, 2, 3, 4, 4, 5])
print(data) # {1, 2, 3, 4, 5}
# 집합 자료형 초기화 방법 2
data = {1, 1, 2, 3, 4, 4, 5}
print(data) # {1, 2, 3, 4, 5}
집합 자료형의 연산
a = set([1, 2, 3, 4, 5])
b = set([3, 4, 5, 6, 7])
# 합집합
print(a | b) # {1, 2, 3, 4, 5, 6, 7}
# 교집합
print(a & b) # {3, 4, 5}
# 차집합
print(a - b) # {1, 2}
data = set([1, 2, 3])
print(data) # {1, 2, 3}
# 새로운 원소 추가
data.add(4)
print(data) # {1, 2, 3, 4}
# 새로운 원소 여러 개 추가
data.update([5, 6])
print(data) {1, 2, 3, 4, 5, 6}
# 특정한 값을 갖는 원소 삭제
data.remove(3)
print(data) # {1, 2, 4, 5, 6}