함수와 람다
함수
- 함수(Function)란 특정한 작업을 하나의 단위로 묶어 놓은 것을 의미합니다.
- 함수를 사용하면 불필요한 소스코드의 반복을 줄일 수 있습니다.
함수의 종류
- 내장 함수: 파이썬이 기본적으로 제공하는 함수
- 사용자 정의 함수: 개발자가 직접 정의하여 사용할 수 있는 함수
함수
- 함수를 사용하면 소스코드의 길이를 줄일 수 있습니다.
- 매개변수 : 함수 내부에서 용할 변수
- 반환 값: 함수에서 처리 된 결과를 반환
def 함수명(매개변수):
실행할 소스코드
return 반환 값
더하기 함수 예시
- 더하기 함수 예시 1)
def add(a, b):
return a + b
print(add(3, 7)) # 10- 더하기 함수 예시 2)
def add(a, b):
print('함수의 결과: ', a + b)
add(3, 7) # 함수의 결과: 10
파라미터 지정하기
- 파라미터의 변수를 직접 지정할 수 있습니다.
- 이 경우 매개변수의 순서가 달라도 상관이 없습니다.
def add(a, b):
print('함수의 결과: ', a + b)
print(b = 3, a = 7) # 함수의 결과: 10
global 키워드
- global 키워드로 변수를 지정하면 해당 함수에서는 지역 변수를 만들지 않고, 함수 바깥에 선언된 변수를 바로 참조하게 됩니다.
a = 0
def func():
global a
a += 1
for i in range(10):
func()
print(a) # 10
여러 개의 반환 값
- 파이썬에서 함수는 여러 개의 반환 값을 가질 수 있습니다.
def operator(a, b):
add_var = a + b
subtract_var = a - b
multiply_var = a * b
divide_var = a / b
return add_var, subtract_var, multiply_var, divide_var
a, b, c, d = operator(7, 3)
print(a, b, c, d)
람다 표현식
- 람다 표현식을 이용하면 함수를 매우 간단하게 작성할 수 있습니다.
- 특정한 기능을 수행하는 함수를 한 줄에 작성할 수 있다는 점이 특징입니다.
def add(a, b):
return a + b
# 일반적인 add() 메서드 사용
print(add(3, 7)) # 10
# 람다 표현식으로 구현한 add() 메서드
print((lambda a, b: a + b)(3, 7)) # 10
람다 표현식 예시: 내장 함수에서 자주 사용되는 람다 함수
array = [('홍길동', 50), ('이순신', 32), ('아무개', 74)]
def my_key(x):
return x[1]
print(sorted(array, key=my_key)) # [('이순신', 32), ('홍길동', 50), ('아무개', 74)]
print(sorted(array, key=lambda x: x[1])) # [('이순신', 32), ('홍길동', 50), ('아무개', 74)]
람다 표현식 예시: 여러 개의 리스트에 적용
list1 = [1, 2, 3, 4, 5]
list2 = [6, 7, 8, 9, 10]
result = map(lambda a, b: a + b, list1, list2)
print(list(result)) # [7, 9, 11, 13, 15]
특히 유용한 표준 라이브러리

자주 사용되는 내장 함수
# sum()
result = sum([1, 2, 3, 4, 5])
print(result)
# min(), max()
min_result = min(7, 3, 5, 2)
max_result = max(7, 3, 5, 2)
print(min_result, max_result)
# eval()
result = eval("(3+5)*7")
print(result)
# sorted()
result = sorted([9, 1, 8, 5, 4])
reverse_result = sorted([9, 1, 8, 5, 4], reverse=True)
print(result)
print(reverse_result)
# sorted() with key
array = [('홍길동', 35), ('이순신', 75), ('아무개', 50)]
result = sorted(array, key=lambda x: x[1], reverse=True)
print(result)
순열과 조합

- 순열: 서로 다른 n개에서 서로 다른 r개를 선택하여 일렬로 나열하는 것
- {'A', 'B', 'C'}에서 두 개를 선택하여 나열하는 경우: 'ABC', 'ACB', 'BAC', 'BCA', 'CAB', 'CBA'
from itertools import permutations
data = ['A', 'B', 'C'] # 데이터 준비
result = list(permutations(data, 3)) # 모든 순열 구하기
print(result)
- 조합: 서로 다른 n개에서 순서에 상관 없이 서로 다른 r개를 선택하는 것
- {'A', 'B', 'C'}에서 순서를 고려하지 않고 두 개를 뽑는 경우: 'AB', 'AC', 'BC'
from itertools import combinations
data = ['A', 'B', 'C'] # 데이터 준비
result = list(combinations(data, 2)) # 2개를 뽑는 모든 조합 구하기
print(result) # [('A','B'), ('A', 'C'), ('B','C')]
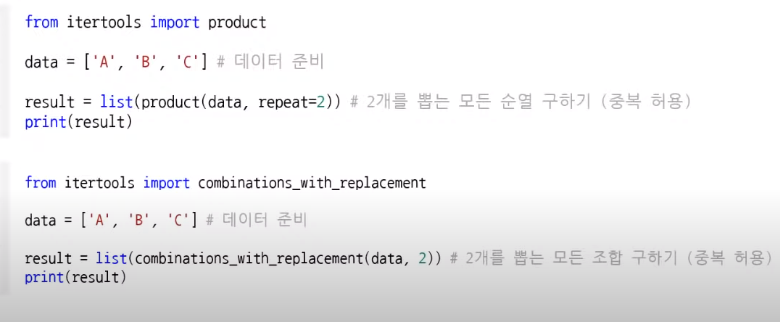
중복 순열과 중복 조합
'코딩테스트 준비 > python' 카테고리의 다른 글
| 그리디 & 구현 # 2 (0) | 2020.11.25 |
|---|---|
| 그리디 & 구현 # 1 (0) | 2020.11.25 |
| 파이썬 문법 #3 (0) | 2020.11.19 |
| 파이썬 문법 #2 (0) | 2020.11.18 |
| 파이썬 문법 #1 (0) | 2020.11.18 |